Attention Mechanism
(This passage contains 0 words)
With the development of large language models, attention mechanism has been an increasingly popular topic for researchers. In this article, we review some of the footstone works in this field, and dive into the Transformer - one of the most widely used architecture in modern model design.
(Conventional Attention Mechanism Left for Future)
Transformer
As the demand for a quick and accurate sequence processing method increases, researchers at Google had proposed a novel architecture without any convolution or recursive structure. This architecture was like a stone thrown into water, leading the development of large language models (LLM) in the following 10 years. The name of that architecture is called the Transformer.
The transformer is more like an architecture than just a model. It is designed mainly based on self-attention mechanism. But unlike conventional attention-based models, it has got rid of recurrent neural networks (RNNs); it is also different from its predecessors in the field of language processing, since its attention blocks are used as the main components, instead of simply an extension to the main system. The architecture of a basic Transformer is given as Figure 1 .
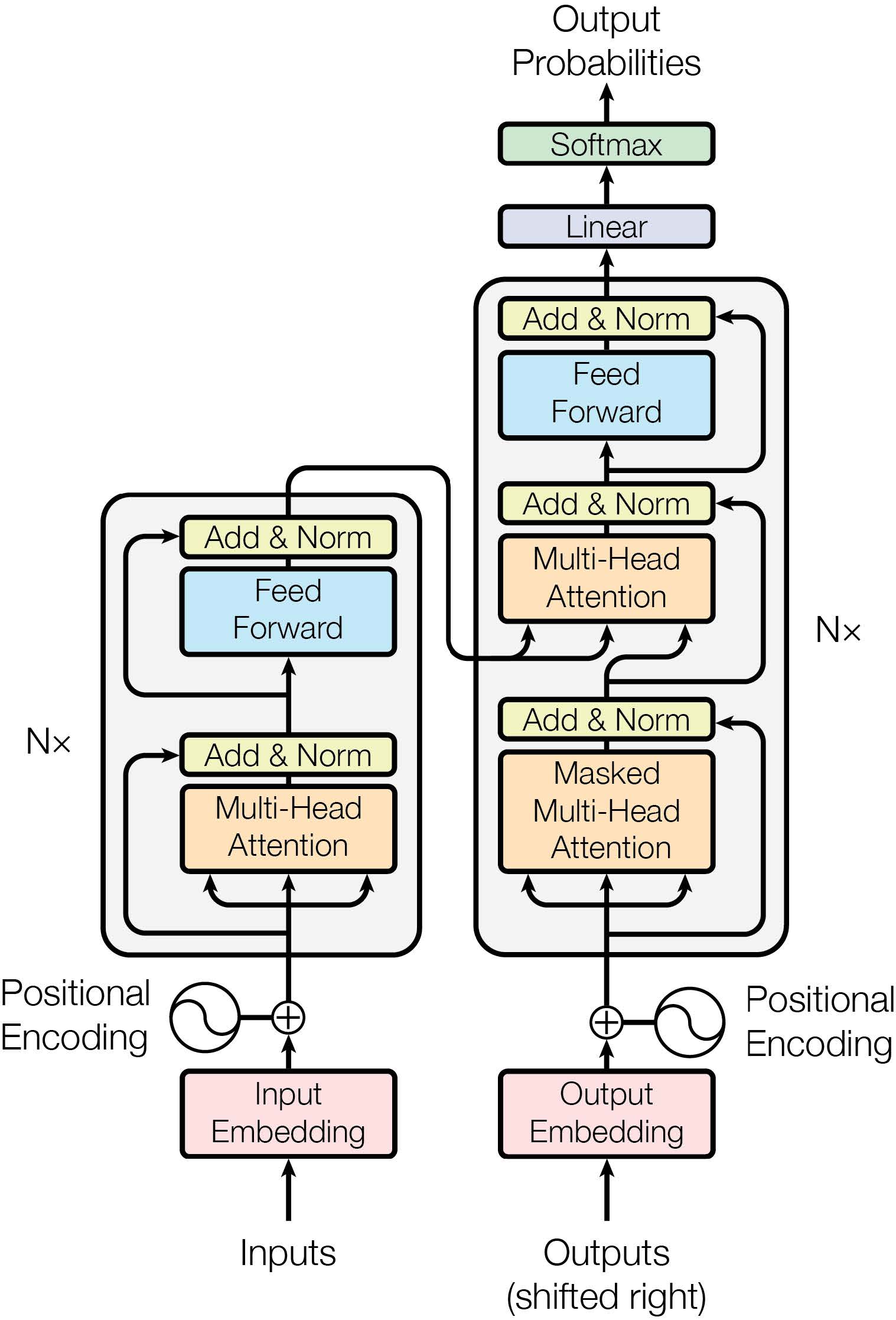
Before we dive into its detailed structure, we first discover one of it most important component – the multi-head attention block.
Multi-Head Attention
The idea of attention in the context of the Transformer is a bit complex. First we review the intra-sentence attention used in encode-decode architectures based on LSTM-Network . At each time step $t$, the relation between $x_t$ and $h_1, h_2, \dots, h_{t - 1}$ (which are used to represent $x_1, x_2, \dots, x_{t - 1}$) can be derived as $s_{ti}$, where $i$ denotes the index of $x_i$ at time step $i$ which $x_t$ is currently related to. The mathematical form is shown as follows. $$ \begin{align} a_{ti} &:= v^\top \tanh(W_h h_i + W_x x_t + W_{\tilde{h}} \tilde{h}_{t - 1}) \\ s_{ti} &:= \text{softmax}(a_{ti}) \text{, where $i < t$} \end{align} $$ Based on these relations, an output $\tilde{h}_t$ is given by $$ \tilde{h}_t := \sum_{i = 1}^{t - 1} s_{ti} h_i $$ From the equations, we can observe that such attention mechanism utilizes the relationship between current input $x_t$ and any previous input $h_i$ ($x_i$), and finally constructs a weighted sum as the final output. The final output at the previous time step $\tilde{h}_{t - 1}$ is also utilized to ensure an explicit information flow in consecutive outputs. In the Transformer, such attention consists of four key concepts – query, keys, values and output .
It is clear that in the language of the Transformer, $\tilde{h}_t$ plays the role of the output, and it is a weighted sum of values $h_i$, where the weights are given by $s_{ti}$, which is essentially a normalized version of $a_{ti}$. According to , a weight is computed by a function of the query and a corresponding key. As for the concept of query and key, a vivid description can be found in : It is like searching for a video with its title (the query) on YouTube, as the search engine will compare the query with a set of keys. The query is strongly related to the decoder, which is about the present; our goal is to find the relation between the present and some tokens in the past, so the keys are actually about the encoder. Clearly, though not evident in , a sequence of $\tilde{h}_i$ plays the role of query, while $h_t$ can be seen as keys (which also serves as values in LSTMN).
References
- Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).
- Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. "Effective approaches to attention-based neural machine translation." arXiv preprint arXiv:1508.04025 (2015).
- Cheng, Jianpeng, Li Dong, and Mirella Lapata. "Long short-term memory-networks for machine reading." arXiv preprint arXiv:1601.06733 (2016).
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
- dontloo, "What exactly are keys, queries, and values in attention mechanisms?", published in StackExchange.